
Abstract
video classification을 위한 pure-transformer based models을 제시했다. input video로부터 spatio-temporal tokens을 추출하고 연속된 transformer layers로 encoding한다. 학습 시 효율적으로 model를 regularise하는 방법으로 기존의 ViT와는 반대로 작은 dataset에서도 좋은 성능을 낼 수 있었다고 한다. 현재 몇몇 benchmarks에서 SOTA인 모델이다.
Introduction
NLP 분야에서 transformer의 등장 이후 매우 빠른 발전을 보여주었고 현재 대부분의 sota모델은 transformer에서 파생되었다고 볼 수 있다. 이는 multi-headed self-attention을 바탕으로 long-range dependencies를 효과적으로 모델링할 수 있었고 input sequence의 국지적인 요소가 아닌 전체를 볼 수 있었기 때문이다.
ViT (Vision Transformer)는 pure-transformer based architecture로 non-local network, video action transformer network 등 CNN과 함께 사용한 network와는 다르다. ViT는 convolution layer와 다르게 inductive bias가 부족하기 때문에 특히 많은 데이터가 필요하다. 하지만 video의 긴 시간에 따른 관계를 modeling하는데 직관적인 선택이라고 생각했고 이를 기반으로 저자는 architecture를 구성했다. 저자가 본 논문에서 제안한 내용은 크게 4가지가 있다.
- input video로부터 추출한 sequence of spatio-temporal tokens을 연산하는 self-attention
- spatial-temporal dimensions따라 model을 factorising 방법 제시
- smaller dataset에서 학습 가능하게 하여 모델 최적화와 pretrained image models사용 감소
- tokenisatoin strategies의 ablation analysis를 통한 최적의 방법 제시
Related Work
3D CNN, 3D CNN + optical flow, I3D, X3D 등등 cnn architecture를 중점적으로 사용한 방법이 있다. 또한, self-attention을 layer나 network 마지막 단계에 적용하는 방법들이 기존에 공개되었다.
Video Vision Transformers
1) Overview of Vision Transformers (ViT)
ViT는 N개의 non-overlapping image patches를 추출하여 linear projection를 실시한다. 그리고 1D tokens으로 rasterise한다. 그리고 classification을 위해 CLS (classification token)을 삽입하고 위치 정보 유지를 위한 positinal embedding을 추가한다.
$$z = [z_{cls}, Ex_{1}, Ex_{2}, ..., E)x_{N}]+p, \;\; x_{i} \in R^{h \times w},\: z_{i} \in R^{d},\: p\in R^{N\times d}$$
이렇게 embedding된 token은 transformer layer로 구성된 encoder에 들어간다. 각 layer l은 Multi-head self-attention, layer normalization (LN), MLP blocks로 구성된다. 수식은 다음과 같다. (residual 포함)
$$y^{l} = MSA(LN(z^{l})) + z^{l}$$
$$z^{l+1} = MLP(LN(y^{l})) + y^{l}$$
MLP는 두 개의 linear projection으로 구성되는데 GELU activation function과 token-dimensionality d로 구분되어 있다.
2) Embedding video clips
두 개의 방법을 사용해 video를 token으로 mapping하고 positional embedding을 추가하고 transformer에 입력하기 위한 차원으로 reshape해주었다. 차원에 대한 수식은 다음과 같다.
$$V \in R^{T \times H \times W \times C} \rightarrow \tilde{z} \in R^{n_{t}\times n_{h}\times n_{w} \times d} \rightarrow z \in R^{N \times d}$$

- Uniform frame sampling
input video clip의 n_t frames을 균일하게 나누고 2D frame으로 각각 embedding해주고 모든 token을 합쳤다. 이는 ViT에서 사용하는 방식과 똑같다.

- Tubelet embedding
non-overlapping하게 input volume으로부터 spatio-temporal tubes를 추출하고 d 차원으로 linear projection을 실시했다. 이 방식은 ViT의 embedding 방식을 3D로 확장한 것으로 볼 수 있다. 수식은 다음과 같다.
$$t \times h \times w, \: n_{t} = \frac{T}{t}, n_{h} = \frac{H}{h},n_{w}=\frac{W}{w}$$
토큰은 각각의 temporal, height, width 차원으로부터 추출된다. 작은 tubelet dimensions을 사용할 경우 토큰의 개수가 많아지는데 이는 computation complexity의 증가로 이어진다. 하지만 tokenisation을 하며 spatio-temporal information이 합쳐지기 때문에 transformer 내에서 temporal information이 fused되는 uniform frame sampling과 큰 차이가 있다고 볼 수 있다.
Transformer Models for Video
Model 1: Spatio-temporal attention
video로부터 추출한 모든 spatio-temporal tokens을 transformer encoder에 입력하는 것이다. layer의 개수에 따라 receptive field가 선형적으로 증가하는 cnn network와 다르게 each transformer layer는 모든 spatio-temporal tokens 간의 쌍 상호작용을 모델한다. 하지만 multi-headed self attention (MSA)는 토큰의 개수에 따라 복잡도가 제곱한다는 단점이 있다. 즉, input frame의 개수에 따라 선형 증가한다.
Model 2: Factorised encoder

분리된 두 개의 transformer encoders로 구성되어 있다.
첫번째는 spatial encoder로 같은 temporal index로부터 추출된 tokens 간의 상호작용만 modeling한다. 각 temporal index는 d차원으로 L_s layer이후 얻을 수 있거나 spatial encoder z^L_s의 output인 token으로부터 global average pooling으로도 구할 수 있다.
$$h_{i} \in R^{d} \: concat \: \rightarrow H \in R^{n_{t} \times d}$$
이렇게 각 temporal index별로 통과한 값을 concatenate하여 temporal encoder로 넣는다. temporal encoder는 L_t 개의 transformer layer로 구성되어 있으며 다른 temporal indices로부터 나온 tokens간의 상호작용을 modeling한다. 최종적으로 나온 token을 classify한다.
해당 architecture는 temporal information의 late fusion과 동일하고 initial spatial encoder는 image classification에서 쓰인 것과 동일하다. CNN architecutre와 유사하게 frame별로 features를 추출하고 이를 합쳐 classification한다. Model 1보다 transformer layer가 많이 쓰임에도 불구하고 적은 FLOPs (fewer floating point operations)가 요구된다.
Model 3: Factorised self-attention

Model 1과 transformer layers의 수가 같다. 하지만 multi-headed self-attention을 모든 tokens에 적용하지 않았다.먼저 동일한 temporal index로부터 추출한 tokens을 self-attention spatially하게 계산하고 동일한 spatial index로부터 추출한 tokens을 self-attention temporally하게 계산한다. 각 self-attention block은 spatio-temporal interactions를 modeling한다. model 1보다 효율적이지만 복잡도는 model 2와 같다.
$$reshape \: z \in R^{1 \times n_{t}\cdot n_{h} \cdot n_{w} \cdot d} \rightarrow R^{n_{t}\times n_{h} \cdot n_{w} \cdot d}$$
spatial self-attention을 계산하기 위해 token z를 위와 같이 reshape해주는 것이 효율적이다. 그리고 temporal self-attention을 위해 아래와 같이 reshape한다.
$$z_{t} \in R^{n_{h}\cdot n_{w} \times n_{t}\cdot d}$$
$$y_{s}^{l} = MSA(LN(z_{s}^{l})) + z_{s}^{l}$$
$$y_{t}^{l} = MSA(LN(y_{s}^{l})) + y_{s}^{l}$$
$$z^{l+1} = MSA(LN(y_{t}^{l})) + y_{t}^{l}$$
spatial-temporal, temporal-spatial간의 성능에서 차이는 없었다. 해당 모델에서는 spatial과 temporal dimensions 변환할 때의 모호성을 피하기 위해 classification token를 사용하지 않았다.
Model 4: Factorised dot-product attention

Model 2, 3과 동일한 계산 복잡도를 지니지만 parameter의 수는 Model 1과 같다. spatial, temporal dimensions 각각 다른 heads를 사용하여 attention weights를 계산하였다. 각 attention operation은 다음과 같다.
$$Attention(Q, K, V) = Softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V$$
$$Q=XW_{q},\: K=XW_{k},\: V=XW_{v},\; X,Q,K,V \in R^{N \times d}$$
핵심 아이디어는 동일한 spatial-temporal index를 가진 tokens에 대해서만 집중하도록 key와 value를 각 query에 대해 수정하는 것이다.
$$K_{s}, V_{s} \in R^{n_{h}\cdot n_{w}\times d}, \; K_{t}, V_{t}\in R^{n_{t}\times d}$$
각 query에 대해서만 attention neighbourhood를 변경하기 때문에 각 heads (spatial, temporal)의 output은 동일한 dimension을 가진다. 따라서 transformer 논문에서도 나왔듯이 아래와 같이 concatenate한다.
$$Y = Concat(Y_{s}, Y_{t})W_{O}, \;\; Y_{s},Y_{t}\in R^{N \times d}$$
Initialisation by leveraging pretrained models
pretrained image models로부터 저자가 제시하는 video models를 사용할 수 있는 방법을 제시한다.
- Positional embeddings
ViT에서 사용하듯이 p를 각 input token에 입력하지만 video models은 n_t 배의 더 많은 존재한다. 따라서 temporally하게 반복하여 position embedding한다.
$$R^{n_{w}\cdot n_{h} \times d} \rightarrow R^{n_{t}\cdot n_{h} \cdot n_{w} \times d}$$
- Embedding weights, E
tubelet embedding tokenisation method를 사용할 때, embedding filter E는 3차원 텐서이다. video classification을 위해 2D filter를 3D filter로 temporal dimension을 따라 filter를 복사하고 평균내어 inflate한다. (I3D에서 사용)
$$E = \frac{1}{t}[E_{image}, ..., E_{image}, ..., E_{image}]$$
추가적으로 central frame initialisation으로 가운데만 제외하고 모든 temporal position에 0으로 둔다. (t/2)
$$E = [0, ..., E_{image}, ..., 0]$$
이 방법을 사용하면 3D conv filter는 initialisation에서 'Uniform frame sampling'과 동일하게 작용하고 이와 동시에 시간 정보도 학습 가능하다.
- Transformer weights for Model 3
Model 3의 block은 pretrained ViT와 다르다. 따라서 spatial MSA는 pretrained된 module로부터 initialise하고 temporal MSA는 weights를 모두 0 값으로 한다. 위의 model 3수식에서 temporal 부분이 시작할 때는 residual connection 역할을 한다.
Empirical evaluation
Experimental Setup
- Backbone architecture : ViT & BERT
- tubelet height and width are equal
- Optimizer : SGD + momentum
- Learning Rate : cosine learning rate schedule
- ViT image model trained either on ImageNet-21K or the larger JFT dataset
Inference
- Input : video clip of 32 frames using a stride of 2
- process multiple views of a longer video and average per-view logits to obtain the final result. (4 views)
multiple view가 뭔지 질문해야함...ㅠ
Ablation study
Input encoding

Model 1 and ViViT-B on Kinetics 400에 Uniform frame sampling과 Tubelet embedding을 비교하였는데 central frame을 사용했을 때, 가장 결과가 좋아서 해당 방법을 지속적으로 사용하였다.
Model variants

모델의 종류에 따라 나온 정확도 (K400), EK는 label 값이 verb, noun으로 나눠져 있어서 verb 값에 대한 정확도를 나타냈다. 위의 결과로 보아 Model의 방식보다는 효율적으로 embedding 방법을 찾는게 더 중요한거 같다. 다만 속도는 다른게 더 빠르다.
Model regularisation

점진적으로 regularizer를 더해가며 성능 향상이 있는 것을 관찰했다. 테이블 2의 모델별 결과값은 모든 regularizer를 적용한 결과값이다. 다만, 데이터의 양의 많은 Kinetics and Moments in Time에서는 위의 방법을 사용하지 않아도 SOTA 결과를 얻은 것으로 보아 적은 dataset에서 높은 정확도를 얻는게 transformer의 발전방향인 것 같다.
Varying the number of tokens


Varying the number of input frames
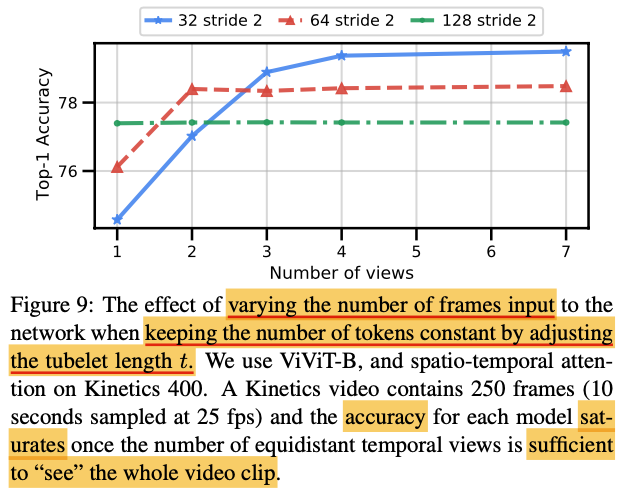
위에서 시행된 실험에서는 input frames을 32로 고정 했었지만 변화하며 이를 실험해보았다. input frames의 수를 늘려가며 token의 개수를 일정하게 하기 위해 tubelet length t를 조절했다. 위의 표에서 알 수 있듯이 일정 수준에서는 model이 input video clip을 모두 볼 수 있어서 정확도가 saturate했다. 동영상 길이가 다를 경우에 이 결과를 참고해야할듯하다.
또한, 해당 논문의 모델은 토큰의 개수를 늘릴 필요 없이 더 긴 영상을 처리할 수 있다는 것을 알 수 있다.

Additional experimental details
Stochastic depth
stochastic depth regularisation은 deep residual net을 training할 때 사용됐다. output layer l(엘)은 input과 동일하게 하기 위해 dropped out된다. 그래서 아래와 같이 네트워크의 depth에 따라 dropping 확률을 선형적으로 증가시켰다.
$$p_{drop}(l) = \frac{l}{L}p_{drop}$$
l : index of the layer in the network
L : total number of layers
Random augment
https://github.com/tensorflow/models/blob/master/official/vision/beta/ops/augment.py 공개된 방법을 사용하였으며 각 video frame에 적용하였다.
Label smoothing
Inception-v3를 training할 때 사용했던 방법이다. lambda는 [0, 1]
$$\tilde{y} = (1-\lambda)y + \lambda u$$
y_tilde : label distribution used during training
y : mixture of the one-hot ground-truth label
u : uniform distribution
Mixup
가상의 training examples를 구축한다. x_i는 input vector, y_i는 one-hot input label, alpha는 [0, 1]
$$\tilde{x} = \alpha x_{i} + (1-\alpha)x_{j}$$
$$\tilde{y} = \alpha y_{i} + (1-\alpha)y_{j}$$
'AI > Paper' 카테고리의 다른 글
| Spatial-temporal pooling for action recognition in videos (2021) 리뷰 (0) | 2021.05.18 |
|---|---|
| GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond (2019) 리뷰 (1) | 2021.05.17 |
| Video Transformer Network (2021) 리뷰 (0) | 2021.04.30 |
| MoViNets: Mobile Video Networks for Efficient Video Recognition (2021) 리뷰 (0) | 2021.04.26 |
| Squeeze-and-Excitation Networks (2018) 리뷰 (0) | 2021.04.20 |
