

리뷰했던 GCNet과 같이 input video frame간의 차이가 매우 연속적이기 때문에 비디오 상 object 간의 특징을 잘 나타내는 frame을 추출하는 방법을 제시한 논문이다.

별, 삼각형, 사각형이 essential frames이고 그 외의 원형이 noise frames이라고 생각한다. (A)에서는 noise frames이 essential frames을 추출하는데 방해가 되는 것을 시각적으로 표현했다. 그래서 (B)와 같이 noise frames을 제외하거나 weight을 적게 주어 essential한 frames을 추출하는 것이 목표이다. 저자는 이 개념을 위의 그림과 함께 표현했다.


frame간의 상관관계를 분석하기 위해 특정 frame(1, 12, 24, 36)을 추출하여 visualization을 실시하였다. 위의 그림에서 볼 수 있듯이 2차원으로 PCA을 수행했을 때, 매우 유사한 분포를 보였다. 따라서 frame간의 spacing이 좁을수록 유사한 이미지를 지니고 있는 것을 알 수 있다.

그 외에도 수식을 적용해 frame간에 차이를 계산하여 비율로 나타냈다.




inception-v1 blocks을 통과한 feature를 temporal-attention과 spatial-attention을 순차적으로 통과하며 frame간에 predicted importance score를 계산하고 낮을 경우 해당 frame은 제외한다.

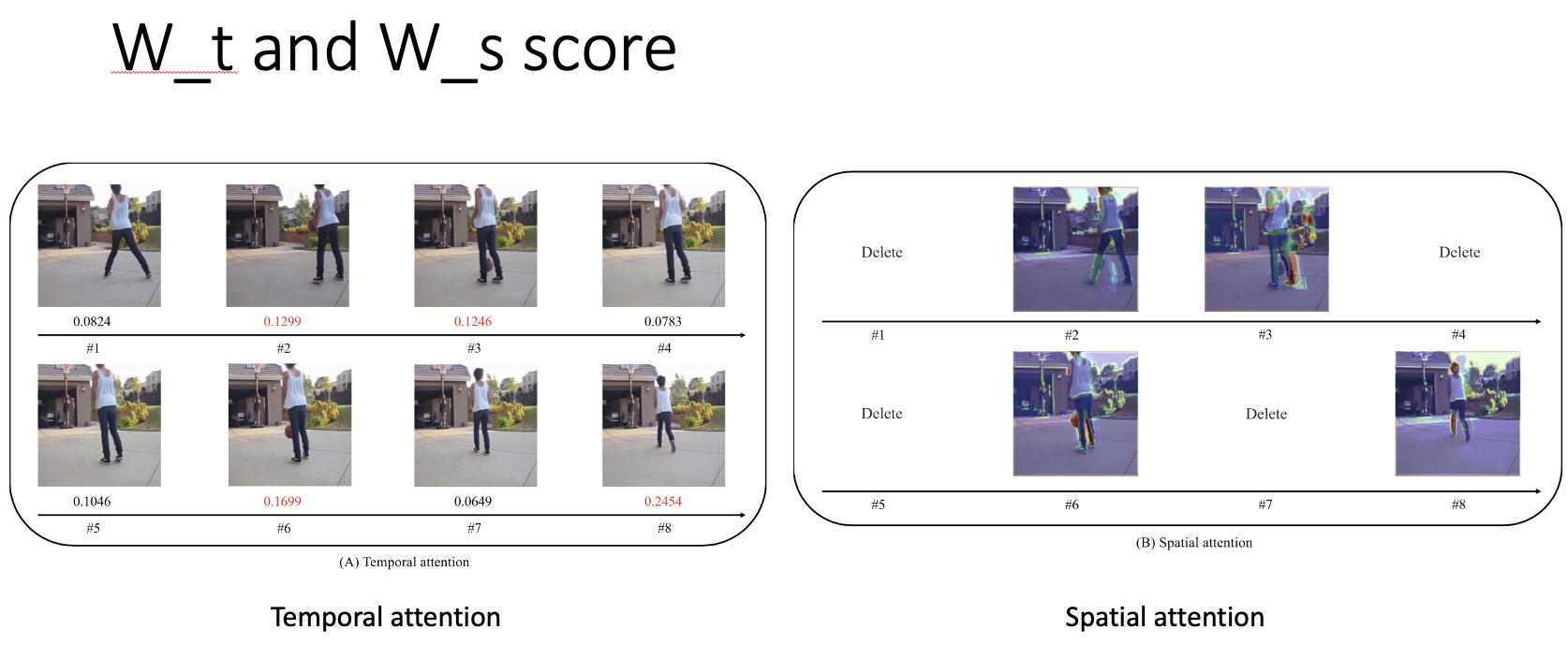
temporal attention block은 frame 간의 importance score를 계산하는 것이 목표이다. 연산된 W_T 값을 큰 수에서 작은 수로 sorting하고 score가 낮을 경우 버린다. 그리고 softmax를 수행하여 [0, 1]사이의 값을 만들어 냈는데 이를 내적하고 residual 연산을 수행하여 spatial-attention block으로 보낸다. temporal attentio block의 architecture는 아래와 같다.


temporal attention block을 통해 들어온 tilde X를 이번엔 channel별로 temporal과 동일한 방식으로 연산을 수행하여 inception-v1 blocks으로 보낸다. 그 후 fc layer with softmax classifier를 통해 예측을 실시한다.

논문에서 제시한 loss function의 경우 최종 final loss function에서 cross-entropy loss와 합하여 최종 loss를 구해내는데 솔직히 왜 넣었는지 모르겠다. STP loss function에 대한 실험결과는 아래와 같다.




temporal attention block을 적용하지 않았을 때, 정확도가 확연히 내려간 것으로 보아 temporal한 부분을 효과적으로 modeling하는 것이 중요한 것으로 보인다.

연산속도와 정확도에서 mean pooling이나 max pooling과 크게 차이가 있지 않은 것으로 보인다.
ref.
슬라이드는 제 논문 세미나 발표자료 입니다.
https://www.sciencedirect.com/science/article/pii/S0925231221006135
'AI > Paper' 카테고리의 다른 글
| Pyramid Feature Attention Network for Saliency detection (2019) 리뷰 (0) | 2021.05.25 |
|---|---|
| SMART Frame Selection for Action Recognition (2020) 리뷰 (0) | 2021.05.24 |
| GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond (2019) 리뷰 (1) | 2021.05.17 |
| ViViT: A Video Vision Transformer (2021) 리뷰 (0) | 2021.05.03 |
| Video Transformer Network (2021) 리뷰 (0) | 2021.04.30 |
