

video classification은 긴 frame feature를 어떤 식으로 modeling하는 것이 가장 중요한 작업이다. long sequence를 처리하는데 LSTM, GRU 등과 같이 RNN 계열의 모델이 CNN 보다는 효과적이다.
저자는 graph 기반으로 frame feature sequence를 모델링하는 방법을 제시하였다. frames과 장면 간의 복잡한 관계를 정립하고 계층적으로 semantic abstraction을 실시하여 video classificiation을 실시하였다.

target이 되는 input data는 timestamps별로 각기 다른 관점? 장면을 가지고 있다. 위의 예시에서 볼 수 있듯이 label은 'cooking show' 이지만 관객, 음식 등과 같이 단일하게 보면 해당 label과 관련 없는 frame이 존재한다. 따라서 저자는 frame level에서 video level로 점진적으로 information을 추출하고 graph를 구성한 뒤 classification을 하는 방식을 제시했다.

graph network는 frame으로부터 extracted된 feature로 node를 구성한다. 그리고 유사한 node는 edge로 연결한다.

앞서 말한 바와 같이 각 frame, shot or event는 graph의 node가 된다. 이러한 node vector 간의 유사도를 측정하여 weighted edge를 잇는다. 이를 위해 adjaceny matrix (인접 행렬)을 구해야 한다. F는 1 개 video의 모든 frame의 vector로 구성된다. consine similarity를 적용해 frame 간의 유사도를 구한다. cosine simliarity의 output은 -1, 0, 1 이기 때문에 adjacency matrix은 해당 값으로 구성된다.
graph convolution network에서 node representation을 전달하기 위해 aggregation function을 사용한다. 이때, 위에 나와있는 G function은 GCN에서 흔히 사용되는 방법을 사용했다. D (digonal node degree matrix)를 사용해 adjacency matrix를 정규화 한다.

video frame sequence는 계층적이어서 학습을 시킴에 따라 adjacency matrix A가 변해야 하는데 고정되어 있다. 그래서 graph의 topology (위상 수학; 작은 변환에 의존하지 않는 성질)가 static하다고 한다. 점진적으로 higher level로 graph topology를 나타낼 수 있어야 한다. 그래서 average pooling, self-attention based pooling을 실시한다.
K 개의 연속적인 노드의 중심을 다음 level의 graph 노드로 사용한다. 순차적으로 수행하면 graph size는 1/K^I번이 된다.

그 다음은 self-attention based pooling이다. local self-attention을 적용하여 weight alpha 값을 구한다. average보다 다음 layer graph의 topology를 더 잘 설명할 수 있다고 한다. alpha가 softmax를 통해 [0, 1] 사이의 값이 나오고 이를 node representation에 적용하여 중요한 node를 집중 시키는 효과가 있다.

기존의 GCN은 fully connected layer를 사용했다. 하지만 저자는 frame sequence를 계층적으로 나타내고 local한 순서를 유지하기 위해 convolution 연산을 적용하였다.


higher level에서 더욱 정확한 representation을 위해 모든 graph에 대해 message passing을 실시한다. 이를 통해 global perspective에서 feature를 생성할 수 있다.
수식을 살펴보자면 node convolution된 것과 pooling을 실시한 것 간의 연산을 통해 최종적으로 다음 level의 graph를 생성할 수 있게 된다.


맨 앞단에서 언급했듯이 frame 간의 유사도를 통해 shot으로 구분지어야 한다. 이때 사용되는 개념을 shot이라고 한다. shot은 관계가 있는 연속적인 이미지로 basic temporal unit이다.
이를 계산하기 위해 dynamic programming으로 segment kernel variances를 최소화하는 목적으로 deep convolutional neural network의 특성을 적용했다. 아래와 같은 결과를 도출할 수 있다.


그렇게 구한 shot boundary의 frame index를 적용해 segmentation을 실시한다.


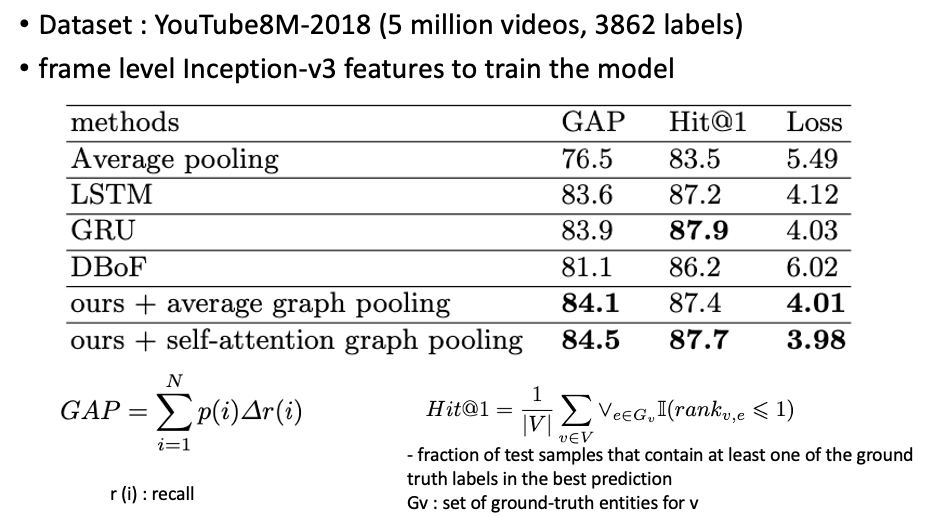
ref.
