
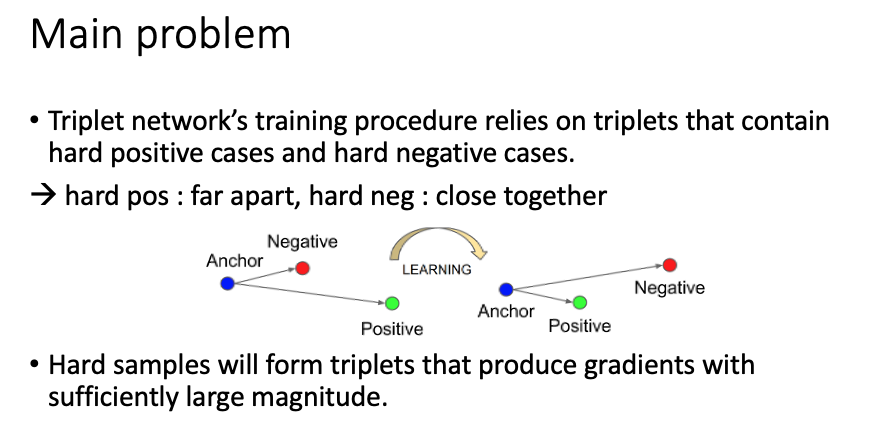
triplet loss를 사용하여 학습시키는 방법의 경우 학습 대상이 되는 데이터 선택이 중요하다. 위의 이미지에서 볼 수 있듯이 anchor와 가까운 negative와 먼 positive간의 거리를 계산하여 positive를 가깝게 negative를 멀게 만들어 준다. 하지만 random choice 또는 해당 anchor에 대해 모든 positive (same label)가 anchor와 이미 가깝다면 loss 값은 0이 되어 불필요한 연산을 하게 되는 것이다.

기존의 triplet loss와 각각의 anchor, pos, neg의 feature를 통합한 global loss를 합쳤다. 그리고 smart sampling 방식을 이용해 low computational complexity에도 위에서 언급한 바와 같이 anchor와 가까운 negative, 먼 positive를 뽑아낼 수 있다고 한다. 마지막으로 smart sampling을 할 때는 hyper-parameter 'k'가 있는데 이를 adaptive하게 조절할 수 있는 방법을 제시했다.
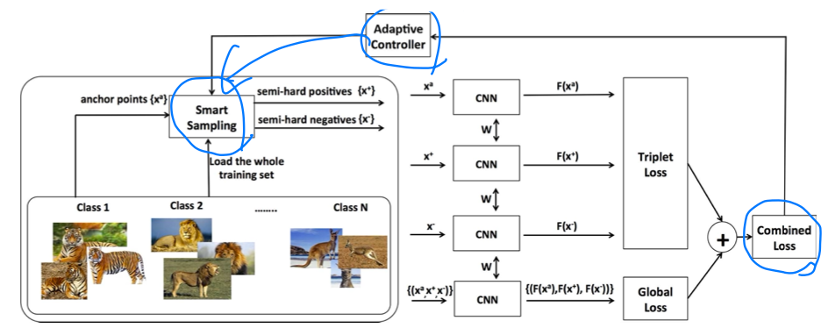




global loss function은 3가지의 역할을 수행한다.
우선 각 anchor에 대한 positive와 negative 값 간의 euclidean distance로 평균 거리를 계산한다. 이때, 4로 나눠서 0보다 크고 1보다 작게 한다고 하는데 왜 그런지는 아무리 찾아봐도 모르겠다. (교수님께 여쭤볼 예정) 어쨌든 이렇게 구한 각 pos, neg에 대한 거리 평균 값으로 positive는 줄어들게 negative는 멀게 한다. 그리고 두 pos, neg에 대한 분산이 줄어들도록 한다. (두 개 분포의 분산을 줄인다면 어떤 장점이 있는지?)

FaceNet에서 사용된 semi-hard mining 기법이다. mini-batch의 anchor가 주어졌을때, 가장 먼 positive, 가장 가까운 negative를 선택하여 학습이 효율적으로 될 수 있도록 하는 기법이다.

smart mining의 목적은 triplet constraint 현상이 일어나지 않도록 negative와 positive를 효율적으로 뽑아내는 것이다. off-line mining strategy로 먼저 ANN을 구성한다. 비슷한 sample들로 approximate하게 나누는 것이다.

각 구간 (set of neighbors S_i) 별로 triplets를 선별한다. embedding region이 적절히 구성되지 않을 경우를 고려하여 negatives를 먼저 선택한다. 이때, 적어도 1개 positive sample이 negative보다 작은 경우가 있는 것을 가정한다. 그리고 positive sample을 선택하여 loss가 0이 되지 않도록 한다.

위에 해당되는 수식은 다음과 같다.
epoch가 계속 될수록 'k' (이미지의 원 넓이 선정)를 줄여가며 exclusion boundary 밖에 있는 negative를 선택한다. 이전에 제외됐던 negative sample이 선택되며 점차 clustering을 좁혀 나가는 것이다.


각 training epoch 시작에 training set를 전부 network에 통과시켜 feature embedding space를 구성한다. training set의 feature들이 graph의 vertex가 된다. 그 후 traverse-add algorithm을 사용해 graph index를 만든다. 각각의 vertex에서 outbound edge가 un-occluded neighbor에 연결한다.
traversable graph는 approximate nearest neighbor set S를 구하는데 효율적으로 컴퓨팅 파워를 사용할 수 있도록 한다. 미리 정의된 nearest neighbors를 거리를 기준 오름차순으로 정리하여 query vertex를 구성한다.

최종적으로 triplet construction을 할 때, positive sample이 정의되면 k 값에 따라 exclusion boundary가 계산된다. 그러면 위에 나온 수식의 조건을 만족하는 negative 값을 list에 포함시킨다.
다만, 한 anchor에 대해 동일한 negative는 사용하지 않는다.


hyper-parameter 'k'는 현재 네트워크에서 충분히 어려운 positive, negative를 뽑을 수 있도록 한다. 그래서 각 epoch 시작마다 'k'값을 estimate한다. 이때의 회귀식을 사용하는데 목적은 high training error, low validation error이다.
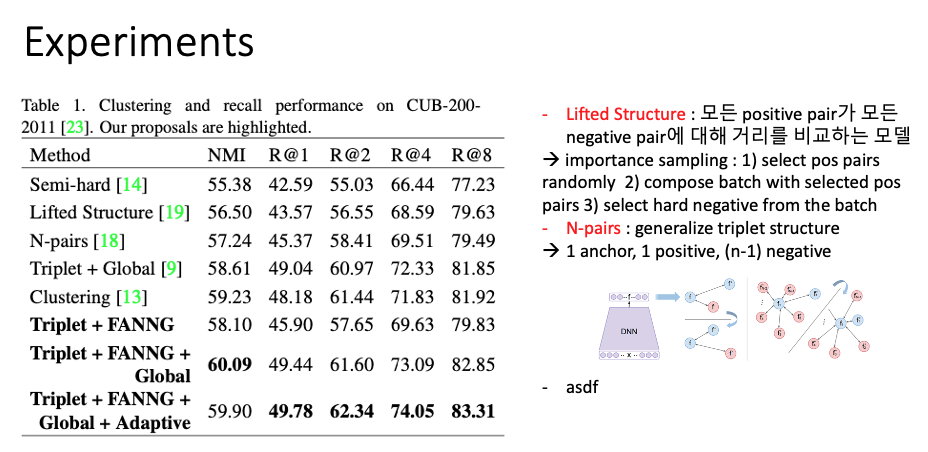


ref.
