
Dataset

CVPR에서 실시한 sign language recognition 대회에서 98% 정답률로 1등을 차지한 모델의 논문이다. 해당 대회 데이터셋에서는 Microsoft Kinect v2 (xbox video)로 촬영하여 RGB, Depth 데이터를 가지고 있다. 43명의 signer가 226개의 signs를 보이고 있으며 36,302개의 비디오 샘플이다. 또한, 20개의 다른 배경에서 촬영하였다.
Abstract

skeleton-based action recognition이 배경, 주체 변화에 독립적인 적용이 가능해서 크게 주목 받고 있다. 그래서 Skeleton Aware Multi-modal SLR (SAM-SLR)을 제시하였다. 특히, Sign Language Graph Convolution Network (SL-GCN)로 embedded dynamics를 모델링하고 Separable Spatial-Temporal Convolution Network (SSTCN)로 skeleton feature를 모델링하였다.
Introduction
sign language는 global body motion과 arm/hand gesture를 사용하여 의미를 전달하는 언어이다. 따라서 표정과 같은 비언어적 표현도 수반되기 때문에 높은 정확도를 나타내기 어려운 분야이다. 그리고 사람의 말투가 다른 것처럼 수화 사용자 간에도 같은 단어를 다르게 표현하기도 하고 심지어 사투리도 존재한다. (국가, 언어별로 다름) 이전까진 3D CNN, RNN, LSTM 등이 사용되었지만 skeleton based method가 action recognition 분야에서 급부상하며 이를 적용했다.
하지만 skeleton-based action recognition methods는 motion capture systems에 의해 ground truth skeleton annotations가 필수여서 부정확할 수가 있다. 따라서 최근 whole-body pose estimation의 발전함에 따라 whole-body keypoints와 pretrained된 whole-body pose estimator를 사용하였다. 논문의 핵심 내용은 다음과 같다.
- pretrained된 whole-body pose estimator를 사용하여 추가적인 annotation effort를 줄였다.
- SL-GCN을 사용하여 skeleton graph로부터 정보를 추출하였다.
- SSTCN for whole-body skeleton features를 제안하여 skeleton features에 대해서 3D CNN보다 더 나은 성능
- SAM-SLR framework를 만들었고 1등했다. (자랑...)
Approach
1) SL-GCN
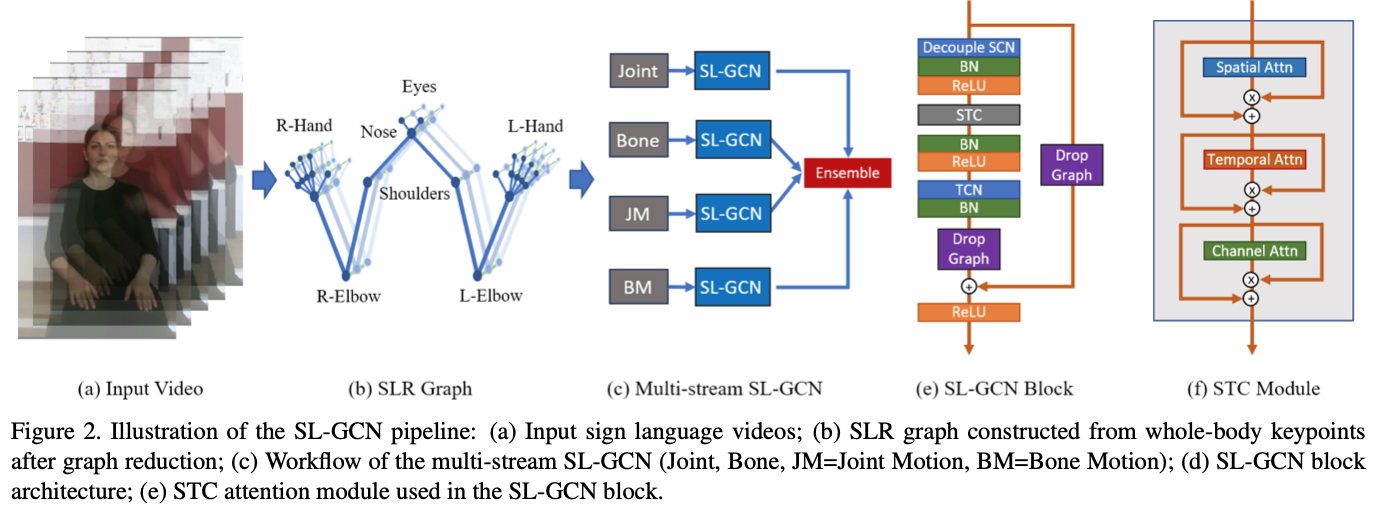
human body skeleton의 역동성을 모델링 하기 위해서 spatio-temporal graph를 만들었다. 이런 graph로부터 motion dynamics를 추출하기 위해 SL-GCN model with attention mechanism를 제안했다. 더 나은 computation power를 위해 multi-stream approach를 적용했다.
1-1) Graph Construction and Reduction
대회에서 제공되는 데이터는 Kinect v2로 촬영된 동영상이다. 하지만 해당 motion capture system은 손에 대해 annotation을 제공하지 않기 때문에 pretrained whole-body pose estimation network (pre-trained HRNet MMPose)를 사용하여 133개의 keypoints를 검출하였다. 그리고 adjacent keypoints를 연결하여 spatio-temporal graph를 생성한다. graph는 모든 facial landmarks, body skeleton, hands, and feet keypoints를 포함한다. d(v_i, v_j)는 skeleton node 간에 가장 짧은 거리에 속하는 node가 1개만 있는 경우를 의미한다.
$$A_{i, j} = \begin{cases}1 & if\: d(v_{i}, v_{j})=1 \\ 0 & else \end{cases} \;\; node\:set\: V = \begin{cases} v_{i, t} | i = 1, ..., N,t=1, ..., T \end{cases}$$
하지만 noise를 줄이고 필요한 정보만을 취하기 위해 graph reduction을 수행한다. 133개의 노드에서 양손에 각 10개와 상체 7개 노드만을 유지한다.
1-2) Graph Convolution
skeleton graph에서 패턴을 검출하기 위해 spatio-temporal GCN (paper : Spatial temporal graph convolutional networks for skeleton-based action recognition)를 spatial partitioning strategy를 적용하였다. (semi-supervised classification with GCN 논문에서 나온 방법을 사용한거 같은데 왜 위의 논문이 언급되었는지???) spatial GCN은 다음의 식과 같이 수행한다. Renormalization trick 사용
$$x_{out} = D^{-\frac{1}{2}}(A+I)D^{-\frac{1}{2}}x_{in}W$$
또한, decoupling graph convolution (paper : Decoupling GCN with DropGraph mod- ule for skeleton-based action recognition)을 적용하여 GCN의 수용량을 늘렸다. decoupling graph convolution에서 graph feature의 channel을 G groups으로 나누고 각 그룹의 채널은 학습가능한 adjacent matrix A를 공유한다. 최종적으로 decoupling group의 convolution값을 concatenated하여 결과값을 낸다.
1-3) SL-GCN Block

SL-GCN block은 decoupled spatial convolutional layer, STC (spatial, temporal, channel wise) attention module, temporal convolutional layer, dropgraph module로 구성되어 있다.
- decouple SCN : GCN modeling 수용량을 늘려준다.
- dropgraph module : 과적합 방지

- STC attention module : spatial, temporal, channel attention 순으로 연결된 형태
spatial-temporal GCN은 10개의 GCN block으로 구성되어 있다. 최종적으로 global average pooling을 각 spatial, temporal dimension에 classification 전에 적용한다.
1-4) Multi-stream Approach

(paper : Skeleton-based action recognition with multi-stream adaptive graph convolutional networks)에서 착안하여 joint, bone, joint motion, bone motion으로 나누어 각각 학습시켰고 ensemble 기법을 사용하였다.
- Bone data : joint data의 기준으로부터 target joint 방향을 vector로 표현했다.
- motion data : adjacent frame 간의 차이를 계산하여 구했다.
2) SSTCN

input video의 60프레임에 해당하는 33 keypoints (1 코, 4 입, 2 어깨, 2 팔꿈치, 2 손목, 22 손)를 추출하고 max-pooling으로 24x24로 down-sampling을 실시한다. 각각의 feature를 2D convolution을 통해 parameter 수를 줄인다.
- Stage 1 : reshape (60 x 33 x 24 x 24) to (60 x 792 x 24) -> 1x1 conv = process temporal information
- Stage 2 : shuffle features and divide into 60 groups -> grouped 3x3 conv = extract temporal and spatial information from different frame.
- Stage 3 : shuffle features and divide into 33 groups -> grouped 3x3 conv = extract spatial information in each frame.
앞선 stage 1, 2, 3에서의 output에는 residual를 더하고 dropout을 각 module에 수행한다. Swish activation function 사용한다.
$$f(x) = x \cdot Sigmoid(x)$$
cross-entropy loss를 one-hot labels에 적용하면 발생하는 overfitting을 막기 위해 label smoothing technique를 수행한다.
$$q'(k|x) = (1-\epsilon)\delta_{k, y} + \epsilon u (k)$$
q'(k|x)는 predicted distribution, epsilon은 hyper-parameter (0~1), u()은 uniform distribution, k는 class 개수를 의미한다. 이를 cross-entropy loss에 적용하면 다음과 같다. 변경된 식은 실제 분포로부터 나온 predicted 분포와 prior 분포 간의 차이에 패널티를 준다.
$$H(q', p) = -\sum_{k=1}^{K}logp(k)q'(k) = (1-\epsilon)H(q, p)+\epsilon H(u, p)$$
3) 3D CNNs
multi-modal ensemble을 사용하면 각 modality의 performance를 올릴 수 있다고 한다. 그래서 (paper : A closer look at spatiotem- poral convolutions for action recognition)의 ResNet2 + 1D architecture를 참고 했다. 해당 논문에서는 3D CNN의 spatial과 temporal convolution을 decouple하여 순차적으로 학습시켰을때 더 좋은 효과를 낸다고 한다. 그래서 저자는 ResNet2 + 1D-18 (pretrained Kinecticss dataset)을 사용했다. 또한, Chinese Sign language이 pretrained된 모델을 사용했다. (1% 성능 향상을 보였다고 함) 그리고 SSTCN과 동일하게 ReLU 대신에 Swish를 적용하고 label smoothing technique를 적용했다.
4) Multi-modal Ensemble
위의 아키텍쳐를 보면 softmax 수행 전에 마지막 FC layer를 통과한 값을 지니고 있다. 각 modality의 validatoin score에 따라 weights를 할당하고 final predicted socre에 따라 weights를 합한다.
$$q_{RGB} = \alpha_{1}q_{skel}+\alpha_{2}q_{RGB}+\alpha_{3}q_{flow}+\alpha_{4}q_{feat}$$
$$q_{RGB-D} = \alpha_{1}q_{skel}+\alpha_{2}q_{RGB}+\alpha_{3}q_{flow}+\alpha_{4}q_{feat}+\alpha_{5}q_{HHA}+\alpha_{6}q_{depthflow}$$
alpha는 hyper-parameter이며 최대값을 class의 indice를 구한다. early fusion 등 여러 ensemble 방법을 사용했지만 위의 방법이 best accuracy를 보였다.
Experiments

1) Whole-body Pose Keypoints and Features
MMPose에서 제공되는 pre-trained HRNet whole-body pose estimator를 사용했다. Randomly sampling, mirroring, rotating, scaling, jittering, shifting으로 data augmentation을 적용했다. 비디오 frame의 sample length를 150 사용했고 150이하면 채워질때까지 비디오를 반복했다.
2) RGB Frames and Optical Flow
모든 RGB video의 frame을 이미지로 저장하여 속도를 높혔다. Optical flow는 paper : Temporal segment networks: Towards good practices for deep action recognition에 나오는 process대로 진행하였고 TVL1 algorithm(paper : A duality based approach for realtime TV-L1 optical flow )을 사용했다. RGB frames, optical flow frames은 256x256으로 crop, resize를 수행했다. training 중에는 각 비디오에서 랜덤하게 연속 32개 프레임을 sampled 했고 testing 중에는 uniformly하게 input video에서 5개를 뽑아내 predicted score로 평균을 냈다.
3) Depth HHA and Depth Flow
HHA features를 depth videos로부터 뽑아냈다. HHA는 horizontal disparity, height above the ground, angle normal을 의미하는데 이런 특성은 depth information을 RGB-like 3-channel output으로 encode한다. gray-scale depth video를 사용하는 것보다 더 나은 성능을 보여주었다. 사용된 데이터셋에서 depth video에 mask가 있어서 HHA feature을 만들 때, 해당 부분은 0으로 채웠다. 이는 위의 사진에서 검은 부분이 masked된 부분이다. HHA feature도 RGB frame과 동일하게 preprocess 과정을 거쳤다. 또한, RGB에서 optical flow를 추출한 방법과 동일하게 HHA에도 적용하여 depth flow를 추출했다.
Result


'AI > Paper' 카테고리의 다른 글
| Squeeze-and-Excitation Networks (2018) 리뷰 (0) | 2021.04.20 |
|---|---|
| Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset (2017) (0) | 2021.04.18 |
| Deep residual learning for image recognition; ResNet (2015) (0) | 2021.03.29 |
| Going deeper with convolutions; GoogLeNet (2014) (0) | 2021.03.29 |
| Very deep convolutional networks for large-scale image recognition; VGGNet (2015) (0) | 2021.03.29 |
