ResNet
1) 개요
- very deep networks using residual connections
- 152 layers
- ILSVRC 15 winner
- Between 20 and 56 layers 'plain' convolutional networks, the deeper network has higher training error and test error.>
- Try to resolve degradation problem with deeper network which isn't caused by overfitting.

Residual Block

- Use network layers to fit a residual mapping instead of directly trying to fit a desired underlying mapping
- Former method was getting the optimal H(x) by passing through just 2 weight layers. But, residual block's goal was getting H(x) - x (difference between output and input) -> weights will be trained to get H(x) - x
if F(x) = H(x) - x -> H(x) = F(x) + x
- If identity mappings are optimal (F(x) = 0), simply drive the weights of the multiple nonliear layers toward 0.
- No increase of computing power (no extra parameter)
- possible to optimize deeper net
- dimensions of x and F(x) must be equal -> If not, perform as linear projection Ws each F and x.
(This will lead time complexity and model size are doubled)
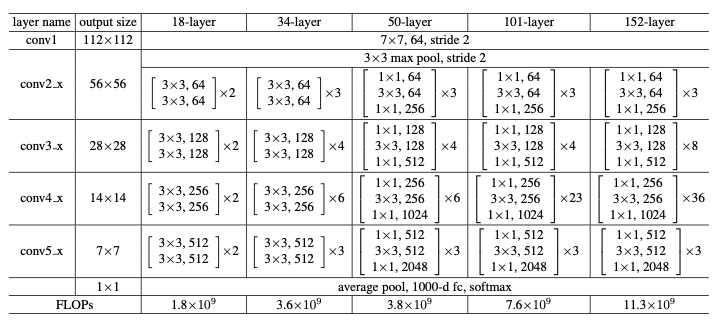
Architecture
- stack residual blocks
- every residual block has two 3x3 conv layers
- periodically, double # of filters and downsample spatially using stride 2 -> reduce activation volume by half
- additional conv layer at the beginning (stem)
- No FC layers at the end (only FC 1000 to output classes)
- For deeper networks, use 'bottleneck' layer to improve efficiency (put 1x1 conv layer)

Training ResNet
1) hyper parameters
- BN after every CONV layer
- 3x3 conv layer
- Xavier initialization from He et al.
- SGD + Momentum (0.9)
- LR : 0.1, divide by 10 when validation error stop decreasing
- mini-batch size = 256
- wegith decay 0.00001
- no dropout used
- only one max-pooling (stride 2 to reduce feature-map size instead of pooling)
2) Experiment
- VGG-19
- residual net : with 34 layers shortcut connection per 2 conv layer
- plain net with 34 layers


2) More than 1000 layers

- 1202-layer is worse than 110-layer although both have similar training error.
- They think this result is because of overfitting. Deeper layers network needs a large dataset.
Ref.
