Instance-based learning으로 별도의 모델 생성없이 인접 데이터를 분류 또는 예측에 사용 (비선형)
Nearest neighbors
1) 새로운 데이터에서 가장 가까운 거리에 있는 이웃값들의 범위를 의미함
- k-nearest neighbor의 k는 설정할 거리를 의미함
특징
1) intance-based learning : 관측치 (instance) 만을 이용하여 새로운 데이터에 대한 예측
2) memory-based learning : 모든 데이터를 메모리에 저장한 후, 예측 시도
3) lazy learning : 모델을 적용하지 않고 테스팅 데이터가 들어와야 작동하는 알고리즘을 의미
장점
1) 데이터 내의 노이즈에 영향 x
2) 학습 데이터 수가 많을 경우 효과적이다.
3) 메모리 기반 방식의 분류기여서 새로운 훈련 데이터에 즉시 적용 가능하다.
단점
1) 하이퍼 파라미터 값을 설정해줘야 한다.
2) 학습 데이터 간의 거리를 모두 측정해야 하므로 데이터 수가 많을 경우 소요 시간이 증가한다.
3) 대규모 데이터셋의 경우 저장 공간에도 주의해야 한다.
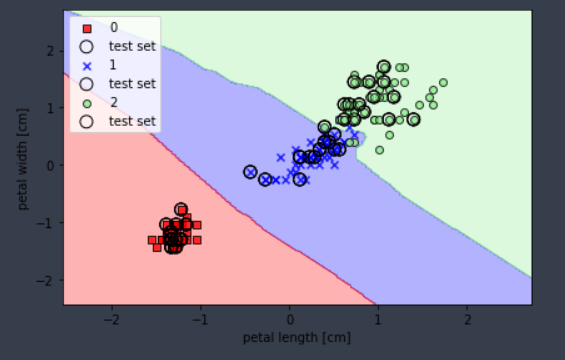
분류 알고리즘
- 인접한 k 개의 데이터로부터 majority voting을 시행했을 때, 인접 데이터들의 다수의 Y 값을 따라간다.
1. 분류할 관측치 x를 선택
2. x로부터 인접한 k개의 학습 데이터 탐색
3. 탐색된 k개 학습 데이터의 majority class 정의
4. c를 x의 분류결과로 반환
예측 알고리즘
- 인접한 k 개의 데이터로부터 majority voting을 시행했을 때, 인접 데이터들의 Y 평균을 따라간다.
1. 예측할 관측치 x를 선택
2. x로부터 인접한 k개의 학습 데이터 탐색
3. k개 데이터의 평균을 x의 예측 값으로 반환
k 선택
1) 1 <= k <= 전체 데이터 개수
2) k값이 너무 작다면 overfitting, 크다면 underfitting 가능성이 있다.
distance 선택
- 거리측정법은 매우 다양하다.
- 데이터 간의 단위, 분산 등이 다를 수 있기 때문에, 정규화를 통해 맞춰주는것 또한 중요하다.
1) Euclidean distance
- x, y값 간 차이 제곱합의 제곱근 (직선거리)

2) Manhattan distance
- x, y값 간 차이의 절대값의 합 (격자)
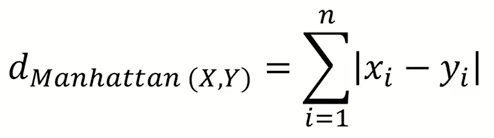
3) Mahalanobis distance
- 변수 내 variance, co-variance를 모두 반영하여 계산
- 공분산 행렬이 단위행렬일 경우 euclidean distance와 같지만 아니라면 타원의 형태가 나타남

4) Correlation distance
- correlation은 -1 <= r <= 1 범위 안의 값이어야 하며, 데이터간 유사성 ( 패턴 )을 구하는데 사용
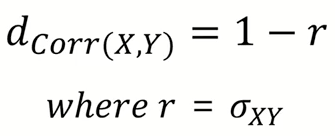

5) Spearman rank correlation distance
- p는 spearman correlation
- 데이터의 rank를 이용하여 correlation distance 구한다.
- 순위 (RANK)로 되어 있는 데이터의 거리를 계산하는데 사용한다.
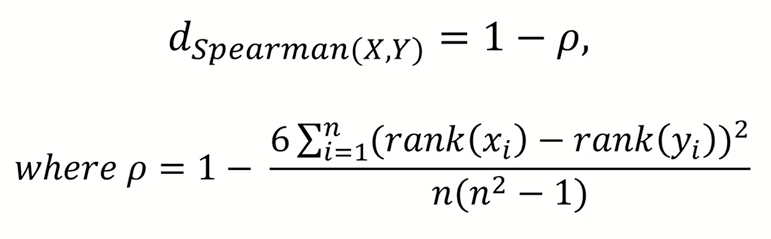
Weighted k-NN
1) 같은 범주 내에서도 데이터 간의 가중치를 단순히 평균을 취하는 것이 아니라 범주 내에서도 거리에 따라 가중치를 둔다.
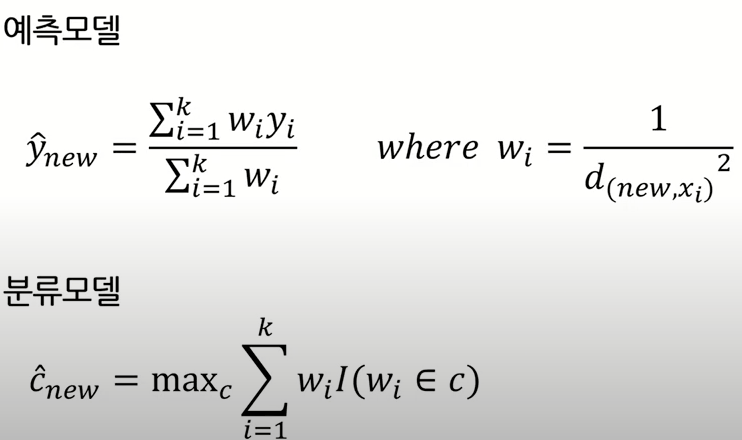
코드 예시
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 5, p = 2, metric = 'minkowski')
knn.fit(X_train_std, y_train)
김성범 교수님의 강의를 정리하였습니다. www.youtube.com/watch?v=W-DNu8nardo
'AI > Machine Learning' 카테고리의 다른 글
| Random Forest (0) | 2021.02.19 |
|---|---|
| Support Vector Machine; SVM (0) | 2021.02.18 |
| Overfitting (과적합) (0) | 2021.02.17 |
| Decision Tree (0) | 2021.01.21 |
| 주성분 분석 (PCA) (0) | 2021.01.04 |
