

기존의 salient detection은 CNN backbone network 사용하여 이미지의 특징을 추출해낸다. 이 방법은 local detail이나 global information을 추출하기 보다 semantic meaning에 조금 더 집중한다. 그래서 저자는 CNN을 사용하지 않고 새로운 network를 구성했다.

기존의 network에 module을 추가하면 과하게 복잡해지고 그에 따라 memory consumption과 computational cost가 높아진다. 그래서 저자는 높은 해상도의 feature map을 유지할 수 있도록 충분히 깊은 네트워크와 낮은 computation cost를 얻을 수 있었다고 한다.


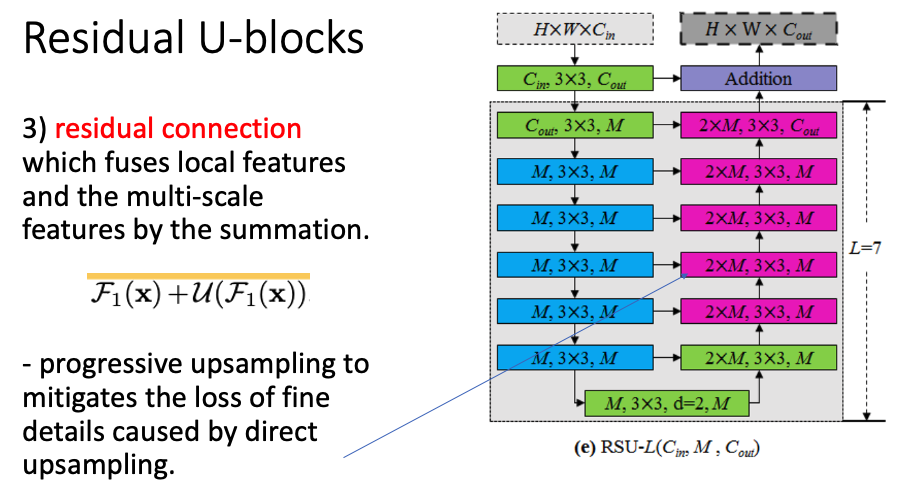
RSU는 intra-stage multi-scale features를 찾아낸다. 총 3가지로 구성된다. local feature extraction을 위해 input을 평범?한 conv layer에 넣고 해당 값을 최종 output shape과 같게 한다. encoder-decoder를 동일한 크기로 쌓아서 점진적인 downsampling을 통해 multi-scale feature를 뽑는다. 마지막으로 residual connection을 사용해 각각의 scale에서 추출된 local feature를 추가한다. 또한, 순차적으로 upsampling하여 정보 손실을 막는다.

residual block과의 차이점으로 feature 그대로를 더하는게 아니라 layer를 한번 통과한 feature를 추가함으로써 multiple scale 정보를 얻도록 한다. 그리고 우측 그래프에서는 plain conv block보다 layer가 복잡해 보이지만 실험적으로는 그렇지 않다는 것을 알려주고 있다.

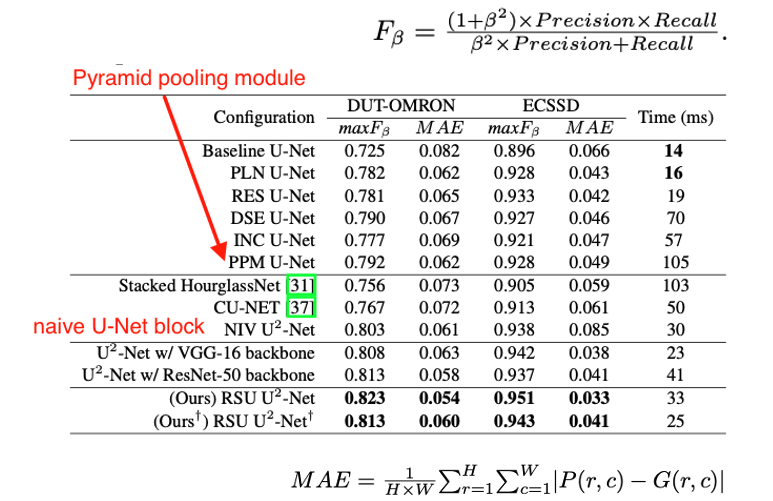

ref.
